Around the World in 800 Billion Bases
 On Tuesday 17 January 2006 the Wellcome Trust Sanger Institute’s World Trace Archive database of DNA sequences hit one billion entries. The Trace Archive is a store of all the sequence data produced and published by the world scientific community, including the Sanger Institute’s own prodigious output as a world-leading genomics institution.
On Tuesday 17 January 2006 the Wellcome Trust Sanger Institute’s World Trace Archive database of DNA sequences hit one billion entries. The Trace Archive is a store of all the sequence data produced and published by the world scientific community, including the Sanger Institute’s own prodigious output as a world-leading genomics institution.
To grasp how much data is in the Archive, if it were printed out as a single line of text, it would stretch around the world more than 250 times. Printing it out on pages of A4 would produce a stack of paper two-and-a-half times as high as Mount Everest.
Each entry is a piece of genetic information averaging 864 characters long. Scientists can search these sequences and piece them together to build up the whole genetic information of organisms – mice, fish, flies, bacteria and, of course, humans.
The Archive is 22 Terabytes in size and doubling every ten months – perhaps the largest single scientific database in Europe, if not the world.
“At 22 000 GB the Trace Archive is in the Top Ten UNIX databases in the world. That’s not bad for a research organisation of 850 employees in the countryside just outside Cambridge.
“It is possibly the biggest single (acknowledged) scientific RDBMS database in Europe, if not the world.”
Martin Widlake Database Services Manager at the Wellcome Trust Sanger Institute
All the data are freely available to the world scientific community (http://trace.ensembl.org/), as a resource to geneticists all over the globe. When a researcher is studying a disease or gene, they can download the genetic information known about the area they are studying.
The data are being actively used by biomedical researchers in academic and commercial organizations. The three internet domains that make most use of the trace archive are .com, .edu and .uk. Dotcoms are responsible for about 80 per cent of download each week – mostly as big ‘customers’, taking vast chunks each visit. Next are US university researchers, followed by UK scientists.
Trace data are the raw results of genetic research to allow them to identify and study genes, to reveal variations (mutations) in genes and to study similarity to genes in other organisms. These are vital starting points for studying and better understanding the biology of health and disease.
By any comparison, the billion records stands above many other familiar repositories. The British Library holds 13 million items: the US Library of Congress holds 115 million items. The Trace Archive holds one billion chunks of unique information.
“Accessing the data becomes a larger and larger problem as the dataset grows. At present it is simple and very quick to access a record if you know its unique identifier as issued by the Sanger Institute, the US National Center for Biotechnology Information (NCBI) database, or the ‘name’ of the trace as given by the organization that originally sequenced that piece of genetic information.
“Scanning the whole dataset for a single genetic sequence, which is a lot like searching for a single sentence in the contents of the British Library, is a massive task. However, the team at the Sanger Institute are working on new methods to make the data easier to search and access”.
Martin Widlake Sanger Institute
The data are held in duplicate, with the NCBI also maintaining a copy: with two sites holding it, a single disaster cannot wipe out the only copy of this vital and heavily used database.
More information
DNA traces
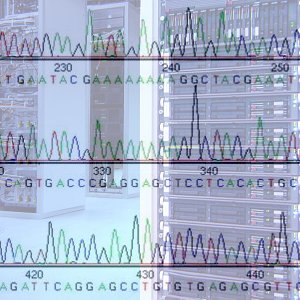
DNA sequencing technology tags each letter of genetic code (base) with a fluorescent chemical. The sequence is read by robots that visualize each letter as a peak of red, green, yellow or blue fluorescence. This image is the ‘trace’.
Each file of raw data is about 200 KB. The trace is interpreted by the robot software and the letters are identified (the bases are ‘called’ in the jargon). The text string of sequence then becomes searchable and faster programs are needed to manage the search of almost one trillion letters (one billion records of 864 bases on average, plus some older records of earlier versions). http://trace.ensembl.org/
The hardware and software
The Database is hosted on a single HP ES45 (a 4-CPU server with 16GB of memory) with the storage consisting of HSV EVA5000s and EVA8000s on a SAN. The data are processed into the database using a cluster of 4 ES45s. The database is an Oracle Database 10g Enterprise Edition.
The Winter Corporation database survey 2005
The Winter Corporation database survey 2005 suggests the Trace Archive would rank fifth behind such giants as AT&T, Yahoo and other large international corporations.
Selected websites
The Wellcome Trust Sanger Institute
The Wellcome Trust Sanger Institute, which receives the majority of its funding from the Wellcome Trust, was founded in 1992. The Institute is responsible for the completion of the sequence of approximately one-third of the human genome as well as genomes of model organisms and more than 90 pathogen genomes. In October 2006, new funding was awarded by the Wellcome Trust to exploit the wealth of genome data now available to answer important questions about health and disease.
The Wellcome Trust and Its Founder
The Wellcome Trust is the most diverse biomedical research charity in the world, spending about £450 million every year both in the UK and internationally to support and promote research that will improve the health of humans and animals. The Trust was established under the will of Sir Henry Wellcome, and is funded from a private endowment, which is managed with long-term stability and growth in mind.


